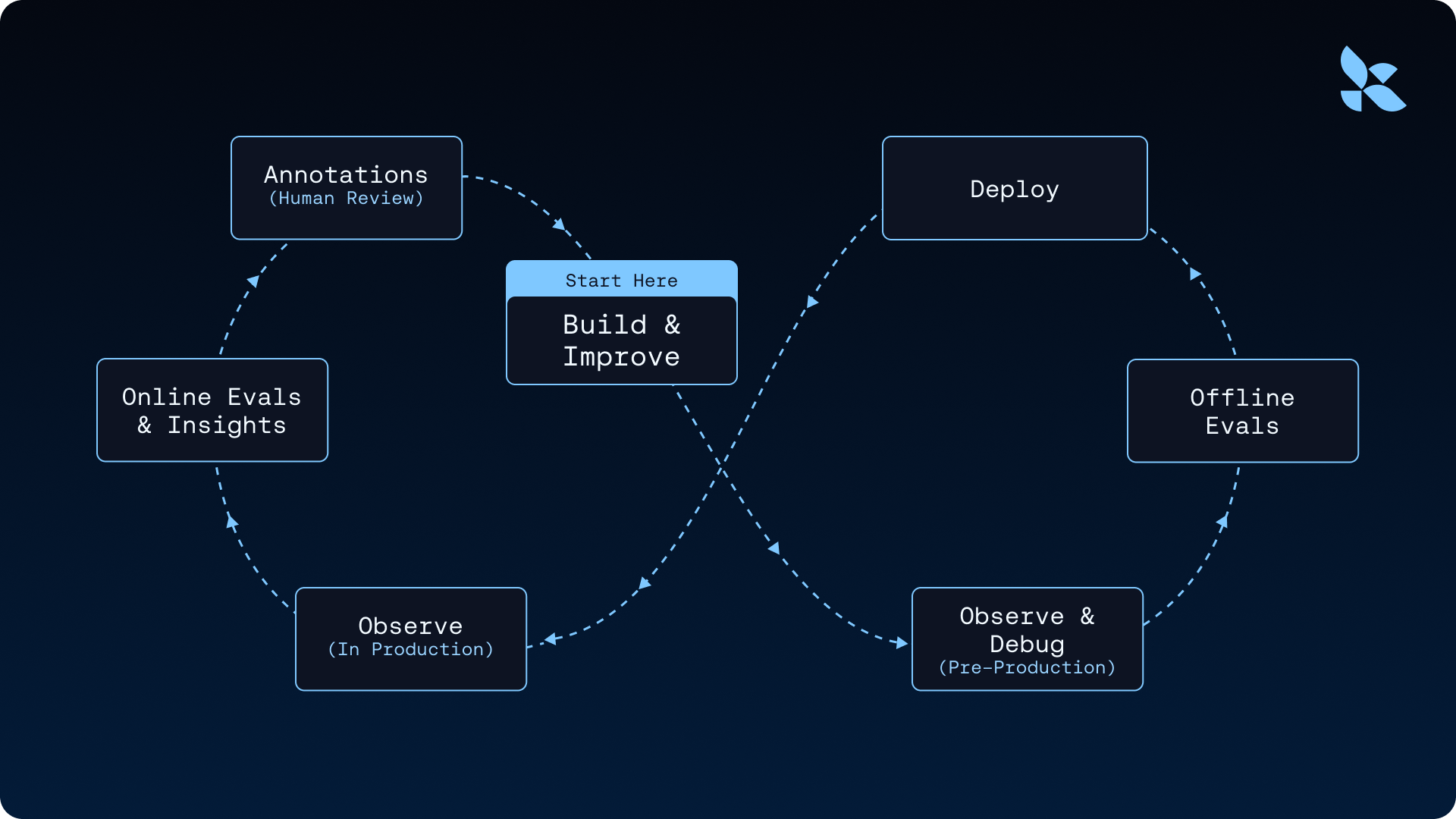
一个好的 Agent 需要什么
你有没有遇到过这种情况。
花了三周调 prompt,调工具定义,调 few-shot 示例,终于把 Agent 跑通了。
演示的时候领导眼前一亮,问了一个灵魂问题:这个能上生产吗?
你心里一沉。
因为你知道,现在这套东西跑在本地,跑在笔记本上,一旦部署到生产环境,面对用户并发、进程崩溃、模型抽风、长时间运行、中途需要人工介入这些状况,基本上撑不住。

这不是你一个人会遇到的问题。
这是整个 AI 行业在 2024-2025 年集体面对的问题。大家都发现,构建一个能跑的 Agent 和构建一个能上生产的 Agent,是两件截然不同的事情。
LangChain 刚发了一篇挺长的 guide,讲的就是这件事。坦率的讲,这是我看过最系统的一次梳理,把「开发态的 Agent」和「生产态的 Agent」之间到底差了什么,讲得很清楚。
我觉得有必要认真聊聊这个话题。
首先,区分两件事
guide 里提了一个我认为非常关键的概念:harness 和 runtime 的区分。
怎么理解呢?
Harness 是你围绕模型构建的那一层,目的是让 Agent 在特定领域里能成功。包括 prompt、工具定义、技能描述,以及支撑模型和工具调用循环的一切。这部分你天天在调,改 prompt、加 few-shot、调 temperature,这些都属于 harness 的范畴。
Runtime 是 harness 下面的那一层,是让 Agent 真正能在生产环境里跑起来的东西。持久化执行、内存管理、多租户隔离、人机交互、监控告警,这些基础设施你在开发的时候根本不会想到,但上线之后每一件都会来敲门。
一个好的 harness 给 Agent 正确的 prompt、工具和技能。
一个好的 runtime 让 Agent 在生产环境里可靠地运行,不会因为进程挂了、版本发布了、用户说「等一下让我确认一下」就崩掉。
这两个东西,缺一不可。
但行业里大多数讨论都在聊 harness——怎么写 prompt、怎么定义工具、怎么做 few-shot,冷不丁冒出一个「RAG 技巧」。Runtime 这部分讲的人少,因为涉及的东西太基础设施了,不好发 demo。
今天我决定好好讲一讲。
Durable execution:一切的基石
先说 durable execution,持久化执行。
这个东西为什么重要?因为 Agent 跑的是一个循环:模型接收 prompt、推理决策、调用工具、观察结果、然后重复。这个循环可能持续几分钟,也可能持续几小时。
不像普通的 web 请求,几百毫秒就返回了,Agent 的执行周期完全不可控。一个研究型 Agent 可能花二十分钟收集资料、整理分析、生成报告;一个辅助决策的 Agent 可能在关键节点停下来,等人工确认某个操作要不要执行。
在这个时间尺度里,进程会挂,服务器会发布,网络会抖动,任何一个环节出问题都不应该让之前的工作全部白费。
你感受最深的大概是两个场景。
第一,长时间运行需要扛住基础设施故障。
假设你的研究 Agent 正在搜集资料,已经完成了十轮工具调用,消耗了大量 token,突然进程崩了。
如果没有任何持久化机制,Agent 只能从头开始,用户的等待时间翻倍,你浪费的 token 费用也翻倍。
你真正想要的是:从上一个完成的步骤恢复,所有状态都保留,不需要重来。
第二,Agent 需要能够真正停下来等。
有时候 Agent 暂停是为了等待人工批准一个操作,比如发送一封重要邮件、执行一笔转账。这个等待可能是三十秒,也可能是三天。
把 worker 进程或者客户端连接绑死在这个窗口里是不现实的。Agent 需要真正释放资源,把 worker 进程让出来,然后等用户回复的时候再精确地从停下的地方恢复。
这两个需求,用同一个机制解决:checkpoint,持久化检查点。
具体怎么做的呢?
Agent 运行在一个托管的任务队列上,每个 super-step 的图执行都会往持久化层写一个 checkpoint。默认是 PostgreSQL,通过 thread_id 作为游标来关联整个运行过程。
进程崩溃了?没问题。run 的 lease 被释放,另一个 worker 会从最新的 checkpoint 恢复。Agent 在等人工输入?没问题。进程释放资源,run 进入休眠状态,一直等到被 resume 为止。
这是整个 runtime 能力的基石。
因为执行可以跨进程边界暂停和恢复,Agent 才能无限期等待人工输入,才能在后台运行,才能在发布中途继续执行,才能同时处理多个并发请求而不破坏状态。
没有 durable execution,其他所有能力都是建立在沙滩上的。
Memory:两种记忆,两种机制
Agent 需要两种不同类型的记忆,这个区分非常重要。
短时记忆是 Agent 在单个对话里积累的东西。消息往来、工具调用、中间状态,在一个 run 里逐步构建。这部分存在 thread 的 checkpoint 里,通过 thread_id 关联,一旦对话结束(概念上)就消失了。
下一条消息来了,如果还是同一个 thread,Agent 能看到之前所有的上下文。这就是短时记忆。
长时记忆是 Agent 跨越对话携带的东西。可能是跨对话学会的用户偏好、项目规范、最佳实践,或者是一个知识库,随着每次查询不断增强。
这些不属于任何一个 thread,它是用户级别或者组织级别的上下文,应该贯穿 Agent 的每一次对话。
checkpoint 做不到这件事,因为 checkpoint 状态的作用域是单个 thread。
长时记忆需要另一个机制。Agent Server 内置了一个 store,这是一个 key-value 接口,记忆按照命名空间元组组织,比如 (user_id, "memories")。存储是跨 thread 持久化的,你在一次对话里写入,下一次对话就能读到。
默认用 PostgreSQL 作为后端,支持语义搜索——通过 embedding 配置让 Agent 可以按照语义检索记忆,而不仅仅是精确匹配。命名空间结构很灵活,你可以按用户、按助手、按组织,或者任意你数据模型需要的组合来组织。

为什么这件事重要?
因为积累数月的记忆是整个系统产出的最有价值的数据之一。它应该存在你能控制的标准格式里,存在你自己的 PostgreSQL 实例里,而不是一个封闭黑箱里。
这样做的好处是,你可以随时迁移到其他模型,可以分析这些数据,可以在 Agent 之外构建其他功能。如果你的记忆被锁在某个封闭系统里,这些可能性都没了。
多租户:三个问题,三层机制
一旦你的 Agent 服务超过一个用户,一系列在单人模式下不存在的问题就冒出来了。
guide 里把这三个问题拆得很清楚,Agent Server 对每个问题都有对应的原语处理。
第一个问题:隔离不同用户的数据。
用户 A 的 run 应该只能访问用户 A 的 thread,只能读取用户 A 的记忆。Custom authentication 作为中间件运行在每个请求上,你的 @auth.authenticate handler 验证传入的凭证,返回用户身份和权限,附加到 run 上下文。Authorization handlers 再用 @auth.on.threads、@auth.on.assistants.create 这些装饰器来控制谁能看什么、改什么,方式是在创建资源时打上所有权元数据标签,读取时返回过滤字典。
Handlers 从最具体到最不具体匹配,所以你可以先从一个全局 handler 开始,随着系统复杂度增长再添加资源特定的 handlers。
第二个问题:让 Agent 能够代表用户操作。
Agent 经常需要用用户的凭证调用第三方服务——读他们的日历,发他们的 Slack,发他们 repo 里的 PR。Agent Auth 处理这个流程的 OAuth 流程和 token 存储,用户认证一次,Agent 在后续的 run 里就能用这个用户的身份操作,不用你自己管理 token 刷新。
第三个问题:控制谁可以操作系统本身。
这是独立于终端用户访问的权限问题。你的团队里谁可以部署 Agent、配置 Agent、查看 trace、更改认证策略?RBAC 处理这个操作员级别的访问控制。
三层组合在一起:终端用户通过你的 auth handler 认证,Agent 通过 Agent Auth 调用第三方服务,你的团队在 RBAC 策略下操作系统。
Human-in-the-loop:让人介入循环
Agent 的执行循环大多数时候需要不间断运行,因为价值就来自这里。但有时候你确实需要一个人在关键决策点介入。
两种典型场景:
场景一,审核 Agent 提议的工具调用。
在 Agent 执行一个重大操作之前——发邮件、转账、删文件——你想让一个人看到它准备做什么,决定怎么回应。比如邮件场景:Agent 起草了一条消息,在发送前暂停。你可以直接批准原样发出,可以修改主题或正文后再发出,也可以拒绝并给出具体修改意见,让 Agent 修订后重试。
场景二,Agent 遇到无法自己解决的决策点。
有时候 Agent 到达一个它无法处理的决策点,不是因为缺少工具,而是因为正确答案取决于人的判断或偏好。与其瞎猜,Agent 可以直接把问题抛出来:「我找到了三个匹配这个模式的配置文件,应该修改哪一个?」「这个应该部署到 staging 还是 production?」你的回答成为 interrupt 的返回值,Agent 从停下的地方继续。
Agent Server 用两个原语处理这个:interrupt() 暂停执行并向调用方暴露一个 payload;Command(resume=...) 用人工响应继续执行。
底层发生了什么?interrupt() 触发 runtime 的 checkpointer 把完整图状态写入持久化存储,通过 thread_id 作为游标关联。进程释放资源,无限期等待。当 Command(resume=...) 到达——可能是几分钟后,可能是几小时后——resume 的值成为 interrupt() 调用的返回值,执行从精确的断点恢复。
因为 resume 接受任意 JSON 可序列化值,响应不仅限于 approve/reject。审核者可以返回修改后的草稿,人类可以提供缺失的上下文,下游系统可以注入计算结果。当并行分支各自调用 interrupt() 时,所有待处理的 interrupts 可以一起暴露,批量 resume,或者按顺序一个一个恢复。
这个能力让审批门控、草稿审查循环、输入验证,以及任何需要人类在中途判断的工作流成为可能。
实时交互:两个问题
人机交互还有另一个维度,除了可以暂停等待人的场景,还有 Agent 在积极工作而用户在线的场景——实时会话。
这类问题有两个。
第一个,流式输出。
如果 Agent 花三十秒产生一个响应,用户只能盯着加载动画,不知道是还在处理、卡住了还是即将失败。用户也无法在完整响应完成前开始阅读,流式解决了这两个问题:部分输出随着 Agent 产生它们实时流向客户端,用户看到响应在眼前逐步呈现。
流式 API 支持多种粒度模式:每个图步骤后的完整状态快照、仅状态更新、按 token 的 LLM 输出,或自定义应用事件。也可以组合使用。Run streaming 作用域是单个 run;thread streaming 打开一个长连接,从 thread 上的每个 run 发送事件,当后续消息、后台 run 或 HITL resume 都在同一个 thread 上触发活动时很有用。
Thread streaming 支持通过 Last-Event-ID header 重连:客户端重连时带上它接收的最后一个事件的 ID,服务器从那里重放,无缝衔接。
第二个,双消息问题。
用户在 Agent 还在处理前一条消息时发了第二条。聊天 UI 里这种事经常发生,有人发了问题,觉得说得不够清楚,在 Agent 还没回完的时候就发了第二条修正。
Runtime 对这种情况有四种策略:
enqueue(默认):新输入等待当前 run 完成,然后按顺序处理。reject:拒绝任何新输入直到当前 run 完成。interrupt:停止当前 run,保留进度,从那个状态处理新输入。当第二条消息是在第一条基础上追加的时候很有用。rollback:停止当前 run,回滚所有进度,包括原始输入,把新消息作为全新 run 处理。当第二条消息替换了第一条的时候很有用。
interrupt 给出最流畅的聊天体验,但要求你的图能干净地处理部分工具调用(interrupt 时发起的工具调用可能没有完成,需要在 resume 时清理)。enqueue 是最安全的默认值,不会出现状态损坏,但用户需要等待。
Guardrails:让策略在代码里,不是 prompt 里
不是所有生产需求都能表达为「让循环持久运行」,有些需要直接塑造循环本身:拦截模型输入、过滤工具输出、对昂贵操作施加限制。

这些策略应该写在代码里,不应该放在 prompt 里。它们需要每次都执行,而不是模型碰巧想起来的时候才执行。
两个具体场景:
场景一,在模型看到之前清除敏感数据。
客服 Agent 处理包含 PII 的用户消息——姓名、邮箱、账号。合规要求这些在记录日志之前就被清除。这个清除必须发生在每次模型调用之前,确定性地执行。
场景二,限制昂贵操作。
可以调用付费外部 API 的 Agent 需要对每次 run 的调用次数设置硬上限,因为一个陷入困惑的模型会高高兴兴调用五十次,在你午饭前烧光你的预算。
这两件事都通过 middleware 处理。Middleware 在定义的钩子(before_model、wrap_model_call、wrap_tool_call、after_model)上包裹 Agent 循环,所以策略在每个相关步骤周围确定性地执行。
LangChain 提供了开箱即用的 middleware:PIIRedactionMiddleware、ModelRetryMiddleware、ModelFallbackMiddleware、ToolCallLimitMiddleware、SummarizationMiddleware、HumanInTheLoopMiddleware、OpenAIModerationMiddleware,你也可以写自定义 middleware 实现应用特定策略。
Middleware 是开源的,但它真正发挥价值是在运行时内部执行时。当 middleware 在 runtime 里运行时,这些策略成为 runtime 支持的每种交互模式的一部分——流式传输、人机交互暂停和恢复、重试、后台 run、长寿命 thread。在实践中,这意味着你的防护栏和仪表化不是「尽力而为」——它们一致地包裹每次模型调用和每次工具调用,在每一个你期望的精确时刻执行,不管 Agent 在做什么。
可观测性:看不到就不能改
你不知道 Agent 在生产环境里会做什么,直到你真的跑起来。
和传统应用不同,传统应用你可以从代码推导出行为,Agent 的执行路径取决于模型在运行时的选择:调用什么工具、传递什么参数、怎么解读结果、什么时候放弃换一个方案。出了问题,你不能重新读一遍函数定义就找到原因,你需要看到到底发生了什么。
一个工单说「Agent 一直问同一个问题」。
没有 trace,你只能从用户描述里猜。有了 trace,你看到完整执行树:用户消息、模型计划响应、调用的工具、返回的结果、下一个生成的消息、陷入的循环。你能筛选高成本的 run 找到消耗大量 token 的案例,筛选错误的 run 找到失败的案例,筛选用户的 run 看到特定客户经历了什么。你能发现跨数千个 run 的模式,这些是任何单个 trace 都无法揭示的。
每个 LangSmith Deployment 自动接入 tracing 项目,开箱即得完整执行树——模型调用、工具调用、子 Agent run、middleware 钩子——带可按用户、时间窗口、成本、延迟、错误状态、反馈或自定义标签查询的结构化元数据。
Trace 是改进循环的基础。Polly 是 LangChain 的 AI 助手,分析 trace 并提炼洞察——常见失败模式、慢工具调用、重复模式——所以你不用手动阅读数千条。Online Evals 自动对生产 trace 运行 LLM-as-judge 或自定义评分器,所以回归问题能被实时捕获。
他们用这个循环把 Deep Agents 在 Terminal Bench 2.0 上提升了 13.7 分,方法仅仅是改变 harness——这个案例完整证明了为什么 Agent 改进循环从 trace 开始。
Time travel:回到过去
可观测性告诉你发生了什么。Time travel 让你问:如果某件事走向不同方向,会发生什么?
驱动场景是调试一个跑偏了的 run。你的 Agent 在 20 步 run 的第 5 步做了一个糟糕决策:调用了错误的工具、误读了工具结果、应该继续的时候问了澄清问题。你想理解为什么,想尝试其他方案而不从头跑整个流程。更一般地说,任何时候 Agent 的路径依赖于特定检查点的状态,你都想要回滚到那个检查点、改状态、让剩余 run 沿不同方向展开的能力。
因为每个 super-step 都会写 checkpoint,run 历史的每个点都已经是一个快照,你可以返回。Time travel 让这个能力显式化:从 thread 历史里选一个 checkpoint,任意修改其状态,然后从那里 resume。被修改的 checkpoint 分叉了 thread 的历史,原来的保持完整,新路径作为自己的分支向前运行。LLM 调用、工具调用、interrupts 都在回放时重新触发,所以分叉走的是真实 Agent 循环,而不是一个存根。
这解锁了一些很难用其他方式构建的模式:调试为什么 Agent 选了工具 A 而不是 B,对比两个 prompt 在相同上游上下文下的表现,从走偏的 run 恢复到上一个良好状态,或者探索许多分叉的反事实来理解模型行为。
代码执行:沙箱里的通用 Agent
只能调用你预先接好的工具的 Agent 局限性很大,受限于你能想到的场景。能跑任意代码的 Agent 是通用目的的:安装依赖、克隆仓库、执行测试、运行数据分析、生成文档、渲染图表。
这是「带函数调用的聊天机器人」和「真正能做成事的 Agent」之间的差距。
任意代码执行需要隔离。如果 Agent 在你的宿主机上跑 rm -rf /,你有大麻烦。如果它读取你的环境变量,API key 就被泄露了。你需要 Agent 执行环境和你在乎的一切之间有一个边界,而且需要在 Agent 写出第一个命令之前就建立好这个边界。
在 Deep Agents 里,隔离通过 sandbox backends 实现。配置一个实现 SandboxBackendProtocol 的后端,Agent 自动获得一个 execute 工具来在沙箱里运行 shell 命令,配合标准文件系统工具使用。没有 sandbox 后端,execute 工具对 Agent 根本不可见。支持 Daytona、Modal、Runloop 和 LangSmith Sandboxes,切换提供商只需改一个配置。
LangSmith Sandboxes 值得单独提一下,因为它与 runtime 的其他部分集成得很好。Templates 用声明方式定义容器镜像、资源限制和 volumes。Warm pools 预启动沙箱并自动补充,消除了交互 Agent 的冷启动延迟。Auth proxy 解决了一个每个团队最终都会遇到的问题:Agent 需要调用有认证的 API,但在沙箱里放凭证是安全风险。Proxy 作为 sidecar 运行,拦截出站请求,自动从 workspace secrets 注入凭证——沙箱代码调用 api.openai.com 时不带任何 header,proxy 在请求出去时加上正确的 Authorization header。密钥永不进入沙箱,Agent 也拿不到它看不到的东西。
一条安全建议值得重复:沙箱保护你的宿主机,不保护沙箱本身。攻击者如果控制了 Agent 的输入(通过被爬网页面的 prompt injection、恶意邮件、下毒的 tool result),可以指示 Agent 在沙箱内运行命令。沙箱把攻击者拦在你的机器之外,但沙箱内部的东西——包括直接放在里面的凭证——都可能被攻陷。Auth proxy 就是为这个而生的。
集成:Agent 不是孤岛
Agent 在能够接入人和组织已经在用的系统时最有用。一个编码 Agent 能访问 GitHub、Linear 和你的 CI 系统时会更强。一个研究 Agent 的输出能进入你的发布流程时更有用。一个内部 Agent 成为平台,当其他 Agent 可以把它作为构建模块来调用时。如果每个集成都是手写的适配器,你的 Agent 就保持孤立。「Agent」和「其他一切」之间的边界变成一堵墙。

开放协议解决的是这个问题——让 Agent 和外部系统互相发现和通信,不需要任何一方知道对方的实现细节。Agent Server 自动提供三个集成面。
MCP(Model Context Protocol) 是连接 Agent 与工具和数据源的开放标准。每个 LangSmith Deployment 自动暴露一个 MCP endpoint,让你的 Agent 可被任何 MCP 兼容客户端发现——Claude Desktop、IDE、其他 Agent、自定义应用——无需你写适配代码。反过来,你的 Agent 也可以调用任何 MCP server(Linear、GitHub、Notion 以及数百个其他)来访问用户已有的工具和数据。
A2A(Agent-to-Agent) 是 Agent 间通信的对应标准,每个部署也自动暴露 A2A endpoint。这让跨部署的多 Agent 架构变得可管理:一个部署里的编排 Agent 可以用双方都理解的协议发现并调用另一个部署里的工作 Agent,不需要手写 HTTP 契约。
Webhooks 处理出站情况:你的 Agent 完成了 run,你想触发下游的事,不需要轮询。在创建 run 时传入 webhook URL,服务器在完成时向那个 URL POST run payload。这就是如何把 Agent run 链入现有工作流的方式——研究 run 完成触发发布管道,每日总结完成通知 Slack,合规检查完成写入审计日志。
Cron:主动工作,不需要人触发
我们到目前为止讨论的 Agent 都是响应式的:用户发消息,Agent 回应。但很多有价值的 Agent 工作是主动的——它按计划发生,不需要人触发。
两种模式特别有意思:
第一种,夜间计算。
在空闲时段做有用工作的 Agent,让用户从累积的思考中获益,而不是等待即时延迟。研究 Agent 每晚运行,追踪你领域的新论文。准备 Agent 在你开始新一天之前审查明天的日历并起草简报。分类 Agent 分类过夜的支持工单,让你的团队走进一个按优先级排列好的队列。工作在没人等待的时候发生,等用户出现时输出已经准备好了。
第二种,健康和监控循环。
定期检查某件事并在发现问题时报错或升级的 Agent。每十五分钟审查告警的值班 Agent,监控你的 staging 环境回归情况的 Agent,按周期巡查违规的合规 Agent。这些需要和面向用户的 run 一样的持久性、tracing 和认证保证,只是没有用户在等它们。
Agent Server 内置了 cron jobs,所以调度的 run 和其他任何 run 一样获得相同的持久性、tracing 和认证保证——不需要维护单独的调度器,不需要搭建第二套可观测性体系。你传入一个标准 cron 表达式(UTC)和输入,服务器按计划触发 run。
两种口味适配不同模式:
- 有状态 cron 把调度绑定到特定 thread_id,所以每次触发的 run 都追加到同一个对话。这适合能看到自己历史的 Agent——每天研究 Agent 在昨天的发现基础上构建,或者监控 Agent 记得它已经标记过什么。
- 无状态 cron 为每次执行启动一个全新 thread,适合不需要 run 之间连续性的批处理式工作。通过
on_run_completed控制 thread 清理:"delete"(默认)在 run 完成后删除 thread,"keep"保留它供以后通过client.runs.search检索。
每个 cron run 都出现在 tracing 里,尊重 auth handlers 和 middleware,并在失败时支持 resume——凌晨三点遇到短暂模型故障的 cron 不会静默失败,会像其他 run 一样重试。一个运营注意事项:用完 cron 记得删掉。在你删除之前它们会一直运行(并计费)。
open harness:不被锁住
agent infra 领域有一个越来越明显的趋势:转向托管方案往往伴随着构建者选择权的减少——被锁在单一模型提供商、被锁进一个封闭 harness、或者 harness 功能被藏在 API 后面(比如服务端压缩生成加密摘要,你没法在一个生态系统之外使用)。
实际后果是:团队失去了对自己 Agent 实际如何运作的可见性,也失去了在它不符合预期时改变它的能力。
关于 vendor lock-in 有一点值得注意:deepagents deploy 的设计目标就是避免它。Harness 是 MIT 许可、完全开源的,Agent 指令使用 AGENTS.md(一个开放标准),Agent 通过开放协议暴露——MCP、A2A、Agent Protocol。没有模型或沙箱锁入,harness 的任何部分都不是黑箱。
此外,Deep Agents 允许你检查、自定义和扩展 Agent 行为的每一层,包括通过 LangChain middleware 配置速率限制、重试逻辑、模型 fallback、PII 检测和文件权限。
Memory 用可插拔后端的虚拟文件系统给 Agent 既有临时工作空间又有持久化跨对话存储。Deep Agents 支持按用户或按助手(或两者)范围的记忆。
沙箱提供商(LangSmith Sandboxes、Daytona、Modal、Runloop,或自定义)是一个配置值。当沙箱存在时,harness 自动添加一个 execute 工具。Sandbox 生命周期(图工厂处理的 thread-scoped 与 assistant-scoped)通过图工厂处理。沙箱内的凭证通过 sandbox auth proxy 管理,所以 API key 从不出现在沙箱代码或日志里。
Skills 和指令从你的 skills/ 目录和 AGENTS.md 自动检测。MCP servers 从 mcp.json 加载。name 字段是唯一必需的配置值;其他都有合理的默认值。
结果是部署可以随时间演进——新 skills、新工具、新记忆策略——不需要全面重写。
说在最后
构建 Agent 是一个深度迭代的循环。
Trace 暴露生产中实际发生的事。在线评估在回归扩大之前捕获它们。记忆让 Agent 随着时间变得更强大。基础设施不仅仅是在支撑在线 Agent——它是让它变得更好的基础。
这篇 guide 覆盖的这些能力——持久化执行、内存、多租户、防护栏、人机交互、可观测性、沙箱代码执行、调度 run,以及更多——是生产 Agent 无法运行就不能缺的基础设施要求。deepagents deploy 把这些都打包好,让团队不需要从头组装,并且在整个过程中保持技术栈开放、可配置、属于你。
坦率的讲,看完 LangChain 这篇 guide,我最大的感受是:行业终于开始认真对待「从 demo 到生产」这中间的距离了。
之前大家都在晒 prompt 效果、晒 benchmark 分数,但真正上了量、上了生产环境,遇到的那些乱七八糟的问题——进程挂了怎么恢复、用户并发怎么办、敏感数据怎么脱敏、长时间运行的 Agent 怎么监控——这些东西很少被系统性地讨论。
LangChain 这次把 runtime 这层基础设施讲得很清楚,我觉得对于正在做 Agent 相关项目的团队来说,是值得认真读一遍的材料。不是说一定要用他们的方案,但至少能让你知道,一个真正能跑在生产里的 Agent,底下需要支撑哪些东西。

以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
原文媒体